介绍
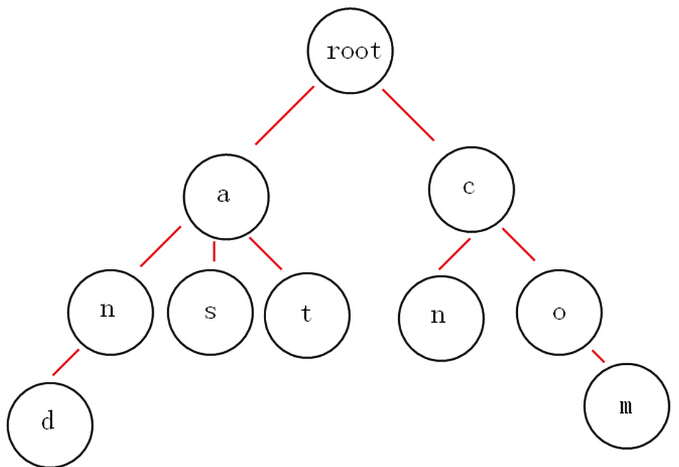
词频统计:
hash或者一个堆就可以完成,但问题来了,如果内存有限呢?这里我们就可以用trie树来压缩下空间,因为公共前缀都是用一个节点保存的。
前缀匹配:
就拿上面的图来说吧,如果我想获取所有以”a”开头的字符串,从图中可以很明显的看到是:and,as,at,如果不用trie树,你该怎么做呢?很显然朴素的做法时间复杂度为O(N2) ,那么用Trie树就不一样了,它可以做到h,h为你检索单词的长度,可以说这是秒杀的效果。
Trie的关键实现
结构体
1 | struct trie |
插入操作(也就是建树)
1 | void insert(char* str) |
查找操作
1 | bool search(*str) |
释放空间(可不写)
1 | void dealTrie(trie* root) |
前缀查找的例子
描述
Ignatius最近遇到一个难题,老师交给他很多单词(只有小写字母组成,不会有重复的单词出现),现在老师要他统计出以某个字符串为前缀的单词数量(单词本身也是自己的前缀).
input
输入数据的第一部分是一张单词表,每行一个单词,单词的长度不超过10,它们代表的是老师交给Ignatius统计的单词,一个空行代表单词表的结束.第二部分是一连串的提问,每行一个提问,每个提问都是一个字符串.
output
对于每个提问,给出以该字符串为前缀的单词的数量.
sample input
banana
band
bee
absolute
acm
ba
b
band
abc
sample output
2
3
1
0
杭电1251题1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
struct trie
{
trie* next[26];
int count;
trie()
{
for(int i=0;i<26;i++)
{
next[i]=NULL;
}
count=0;
}
}root;
void insert(char* str)
{
trie* p=&root;
while(*str)
{
int id=*str-'a';
if(p->next[id]==NULL)
{
p->next[id]=new trie();
}
p->next[id]->count++;
p=p->next[id];
str++;
}
}
int search(char* str)
{
trie* p=&root;
while(*str)
{
int id=*str-'a';
if(p->next[id]==NULL)
{
return 0;
}
p=p->next[id];
str++;
}
return p->count;
}
int main()
{
char str[15];
while(gets(str)&&str[0]!='\0')//注意这儿的输入方式
{
insert(str);
}
while(scanf("%s",str)!=EOF)
{
int cnt=search(str);
printf("%d\n",cnt);
}
return 0;
}